The Main Aspects of XLIFF Standard
There are several standards in the localization industry that make it possible to exchange localizable data between different tools, which are different than proprietary formats.
XLIFF stands for XML Localization Interchange File Format. It’s a standard that specifies the way localizable data is passed between platforms and tools. This standard was approved by OASIS (Organization for the Advancement of Structured Information Standards) in 2002. The current version is 2.1 (released on 02/13/2018), which is backwards compatible with version 2.0 (released on 08/05/2014). You can also find some tools that still support the legacy format from version 1.2.
Version 1.2
Let’s take a quick look at version 1.2 of XLIFF. A document that follows XLIFF 1.2 is composed of one or more file tags. Each file tag corresponds to an original file or source (e.g. database table). Inside of a file tag you will find a header tag that may contain some metadata, like the file name, field names, etc. If you check the following example, it has an internal file tag that represents the actual file. It can also contain an external file tag that has information related to an external file referenced in the XLIFF (e.g. the location). Also, you’ll find a body tag that may contain one or more translation units (trans-unit tags). Each trans-unit tag has a source and a target tag, each one containing the source language and target language content, respectively.

Version 2.0
Even though XLIFF version 1.2 has been used successfully in many scenarios, version 2.0 introduced some improvements. Let’s look at the following example of XLIFF 2.0 and then compare it with version 1.2.
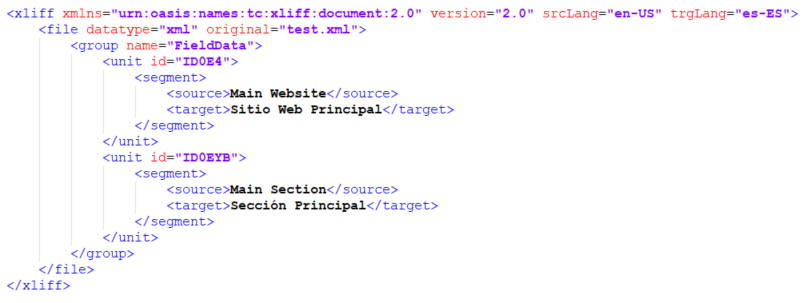
If you check the example above, the source and target languages are specified in the XLIFF tag level. That means that every file tag in a XLIFF document from version 2.0 will be in the same language pair. In version 1.2 this is different because the language pairs are specified at the file tag level. This simplifies the processing and makes it easier to split the content, compared with the possibility of having files with different language pairs in the same document.
Also, the structure is simpler compared with a document from version 1.2.
Another benefit from version 2.0 is that it’s clearer and specifies more constraints and processing requirements. Version 1.2 had ambiguities and lacked constraints and processing requirements.
XLIFF 2.0 also adds the concept of modules. There are different types of modules that add additional features. For example, there is a Change Tracking Module that stores revision information for XLIFF elements and attributes. There is also a Validation Module that defines specific validation rules that can be applied to the target language content. Lastly, there is a Glossary Module that lets you embed glossaries into the XLIFF.
These are just some differences between the standards. You can check version 2.0 more in-depth in the official specification.
Version 2.1
2.1 is the current version of the standard. Besides a major bugfix for the Change Tracking Module, it adds a new ITS Module. It also brings Advanced Validation capabilities. Documents that follow this specification can be fully validated with standardized validation artifacts, without the need for custom validation codes.
For further details, you can check the official specification.
Conclusion
In this blog, I mentioned the main aspects of the XLIFF standard and some differences between each main version, but keep in mind that there are others that are also important, including:
- TMX (Translation Memory eXchange), which is designed to support the exchange of translation memories between computer-based localization tools.
- TBX (TermBase eXchange), which is used to share glossaries between computer-based localization tools.
- SRX (Segmentation Rules eXchange), which describes the ways in which localization tools split the text in segments for processing.
