How to Build a Simple Scraper in Python
It is very common to have a website that contains data you need to analyze, but usually websites present data in HTML format, which can be difficult to work with. Manually copying and pasting into spreadsheets might work if the data set is small, but it will be frustrating and time consuming to use the same technique for bigger amounts of data.
A preferred method to extract information from any website is to use an API. Most large websites provide access to their information through APIs, but this is not always the case for other websites. This is where scraping comes in.
Web scraping is an automated technique used to crawl websites and extract content from them. But before discussing the technical aspects, I need to mention that scraping a website must adhere to a website’s terms and conditions and legal use of data.
Why Python?
I chose Python for this tutorial because of its ease of use and rich ecosystem. There are many libraries that can be used for scraping purposes, but I will use “BeautifulSoup” as a parser and “urllib” as a URL fetcher to walk you through the easiest way to implement a web scraper.
Inspecting the Page
Building a scraper will be an adaptable process that takes layout modifications and website structure into account, this is not a onetime task.
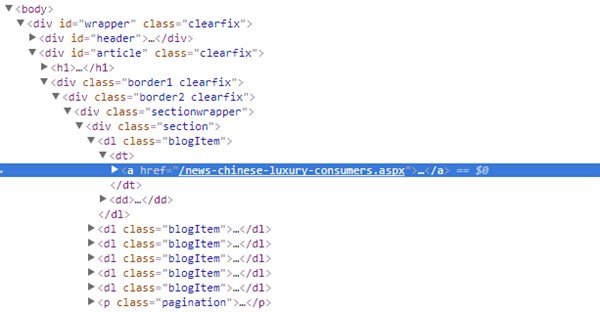
I chose a GPI blog as a source of information for my scraper. As you inspect the HTML code shown in the screenshot below, it turns out that the Div that has all the blog information is <div id=”article”> and each blog item is under <dl class=”blogItem”>.
The Code
Let’s start by importing the libraries we are going to use for this task.
[perl]
# import libraries
import urllib.request as ur
from bs4 import BeautifulSoup
[/perl]
Since the GPI blog has many pages, it’s better to prompt for number of pages to scrape to keep it minimal. This is a good option if you don’t want to go too aggressive on any website, which could get you banned as a spammer.
[perl]
max = input(“How many pages do you want to scrape? “)
count=1
while count < int(max)+1:
url = ‘/translation-blog?page=’ + str(count)
data = ur.urlopen(url).read()
soup = BeautifulSoup(data, ‘html.parser’)
items = soup.find_all(‘dl’, attrs={‘class’: ‘blogItem’})
for item in items:
print(“Blog URL:”, item.find(“a”).get_text())
print(“Blog Title:” , item.find(“a”).get(“href”))
print(“Blog Date:” , item.find(“span”, attrs={‘class’: ‘date’}).get_text())
count += 1
[/perl]
Once we have the number of blog pages we need to scrape, content retrieval will be simple. This will retrieve the blog URL, title and publish date and print it to your console. In a real scenario, you would be interested in getting data into a well-structured more tabular format, Pandas DataFrame is likely to be used.
A DataFrame is an object that stores data in a tabular format, which facilitates data analysis.
Below is how the final code looks:
[perl]
import pandas as pd
import urllib.request as ur
from bs4 import BeautifulSoup
max = input(“How many pages do you want to scrape? “)
count=1
records = []
while count < int(max)+1:
url = ‘/translation-blog?page=’ + str(count)
data = ur.urlopen(url).read()
soup = BeautifulSoup(data, ‘html.parser’)
items = soup.find_all(‘dl’, attrs={‘class’: ‘blogItem’})
for item in items:
blogurl = item.find(“a”).get_text()
title = item.find(“a”).get(“href”)
bDate = item.find(“span”, attrs={‘class’: ‘date’}).get_text()
records.append((bDate, title, blogurl))
count += 1
df = pd.DataFrame(records, columns=[‘date’, ‘title’, ‘url’])
df.to_csv(‘gpiblogs.csv’, index=False, encoding=’utf-8′)
[/perl]
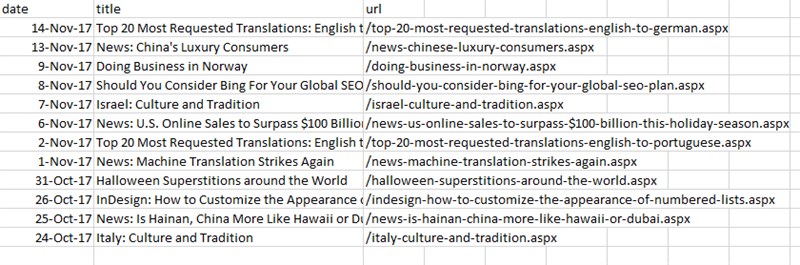
Here is a preview of the output file:
Summary
Building a web scraper in Python is relatively easy and can be accomplished in a few lines of code. Web scraping in general is a fragile approach, though. It is reliable if used with well-structured web pages with static informative HTML tag attributes. APIs (if provided by a website) are the preferred approach since they are less likely to break.
